HDFS Federation(HDFS иБФзЫЯ)дїЛзїН
еЉ†иіµеЃЊ
guibin.beijing@gmail.com
2011.11.25
1. ељУеЙНHDFSжЮґжЮДеТМеКЯиГљж¶Вињ∞
жИСдїђеЕИеЫЮй°ЊдЄАдЄЛHDFSеКЯиГљгАВHDFSеЃЮйЩЕдЄКеЕЈжЬЙдЄ§дЄ™еКЯиГљпЉЪеСљеРНз©ЇйЧізЃ°зРЖпЉИNamespace managementпЉЙеТМеЭЧ/е≠ШеВ®зЃ°зРЖжЬНеК°пЉИblock/storage managementпЉЙгАВ
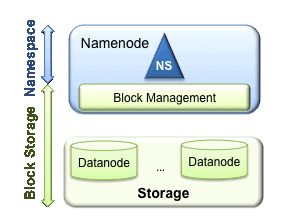
1.1 еСљеРНз©ЇйЧізЃ°зРЖ
HDFSзЪДеСљеРНз©ЇйЧіеМЕеРЂзЫЃељХгАБжЦЗдїґеТМеЭЧгАВеСљеРНз©ЇйЧізЃ°зРЖпЉЪжШѓжМЗеСљеРНз©ЇйЧіжФѓжМБеѓєHDFSдЄ≠зЪДзЫЃељХгАБжЦЗдїґеТМеЭЧеБЪз±їдЉЉжЦЗдїґз≥їзїЯзЪДеИЫеїЇгАБдњЃжФєгАБеИ†йЩ§гАБеИЧи°®жЦЗдїґеТМзЫЃељХз≠ЙеЯЇжЬђжУНдљЬгАВ
1.2 еЭЧ/е≠ШеВ®зЃ°зРЖ
еЬ®еЭЧе≠ШеВ®жЬНеК°дЄ≠еМЕеРЂдЄ§йГ®еИЖеЈ•дљЬпЉЪеЭЧзЃ°зРЖеТМзЙ©зРЖе≠ШеВ®гАВињЩжШѓдЄАдЄ™жЫійАЪзФ®зЪДе≠ШеВ®жЬНеК°гАВеЕґдїЦзЪДеЇФзФ®еПѓдї•зЫіжО•еїЇзЂЛеЬ®Block StorageдЄКпЉМе¶ВHBaseпЉМForeign Namespacesз≠ЙгАВ
1.2.1 еЭЧзЃ°зРЖ
A) е§ДзРЖData NodeеРСName Nodeж≥®еЖМзЪДиѓЈж±ВпЉМе§ДзРЖdatanodeзЪДжИРеСШеЕ≥з≥їпЉМе§ДзРЖжЭ•иЗ™Data NodeеС®жЬЯжАІзЪДењГиЈ≥гАВ
B) е§ДзРЖжЭ•иЗ™еЭЧзЪДжК•еСКдњ°жБѓпЉМзїіжК§еЭЧзЪДдљНзљЃдњ°жБѓгАВ
C) е§ДзРЖдЄОеЭЧзЫЄеЕ≥зЪДжУНдљЬпЉЪеЭЧзЪДеИЫеїЇгАБеИ†йЩ§гАБдњЃжФєеПКиОЈеПЦеЭЧдњ°жБѓгАВ
D) зЃ°зРЖеЙѓжЬђжФЊзљЃпЉИreplica placementпЉЙеТМеЭЧзЪДе§НеИґеПКе§ЪдљЩеЭЧзЪДеИ†йЩ§гАВ
1.2.2 зЙ©зРЖе≠ШеВ®
жЙАи∞УзЙ©зРЖе≠ШеВ®е∞±жШѓпЉЪData NodeжККеЭЧе≠ШеВ®еИ∞жЬђеЬ∞жЦЗдїґз≥їзїЯдЄ≠пЉМеѓєжЬђеЬ∞жЦЗдїґз≥їзїЯзЪДиѓїгАБеЖЩгАВ
1.3 ељУеЙНHDFSзЪДжЮґжЮД
еЬ®ељУеЙНзЪДHDFSжЮґжЮДдЄ≠пЉИHadoop v0.23дєЛеЙНпЉЙпЉМеЬ®жХідЄ™HDFSйЫЖзЊ§дЄ≠еП™жЬЙдЄАдЄ™еСљеРНз©ЇйЧіпЉМеєґдЄФеП™жЬЙеНХзЛђзЪДдЄАдЄ™Name NodeпЉМињЩдЄ™Name NodeиіЯиі£еѓєињЩеНХзЛђзЪДдЄАдЄ™еСљеРНз©ЇйЧіињЫи°МзЃ°зРЖгАВињЩдєЯж≠£жШѓеНХзº姱жХИпЉИSingle Point FailureпЉЙзЪДйЪРжВ£жЙАеЬ®гАВжЬђжЦЗжЙАиЃ≤зЪДHDFS Federationе∞±жШѓйТИеѓєељУеЙНHDFSжЮґжЮДдЄКзЪДзЉЇйЩЈжЙАеБЪзЪДжФєињЫпЉМзЃАеНХиѓіHDFS
Federationе∞±жШѓдљњеЊЧHDFSжФѓжМБе§ЪдЄ™еСљеРНз©ЇйЧіпЉМеєґдЄФеЕБиЃЄеЬ®HDFSдЄ≠еРМжЧґе≠ШеЬ®е§ЪдЄ™Name NodeгАВ
зЃАеНХеЫЮй°ЊдЄАдЄЛзЫЃеЙНHDFSзЪДжЮґжЮДпЉМе¶ВдЄЛеЫЊжЙАз§ЇгАВеЬ®жХідЄ™HDFSйЫЖзЊ§дЄ≠еП™жЬЙдЄАдЄ™NamenodeпЉМињШжЬЙдЄАдЄ™Backup NamenodeгАВNamenodeдЉЪеЃЮжЧґе∞ЖеПШеМЦзЪДHDFSзЪДдњ°жБѓеРМж≠•зїЩBackup NamenodeгАВBackup Namenodeй°ЊеРНжАЭдєЙжШѓзФ®жЭ•еБЪNamenodeзЪДе§ЗдїљзЪДгАВNamenodeдЄ≠еСљеРНз©ЇйЧідї•е±Вжђ°зїУжЮДзїДзїЗдЄ≠е≠ШеВ®зЭАжЦЗдїґеРНеТМBlockIDзЪДеѓєеЇФеЕ≥з≥їгАБBlockIDеТМеЕЈдљУBlockдљНзљЃзЪДеѓєеЇФеЕ≥з≥їгАВињЩдЄ™еНХзЛђзЪДNamenodeзЃ°зРЖзЭАжХ∞дЄ™DatanodeпЉМBlockеИЖеЄГеЬ®еРДдЄ™DatanodeдЄ≠пЉМжѓПдЄ™DatanodeдЉЪеС®жЬЯжАІзЪДеРСж≠§NamenodeеПСйАБењГиЈ≥жґИжБѓпЉМжК•еСКиЗ™еЈ±жЙАеЬ®DatanodeзЪДдљњзФ®зКґжАБгАВBlockжШѓзФ®жЭ•е≠ШеВ®жХ∞жНЃзЪДжЬАе∞ПеНХеЕГпЉМйАЪеЄЄдЄАдЄ™жЦЗдїґдЉЪе≠ШеВ®еЬ®дЄАдЄ™жИЦиАЕе§ЪдЄ™BlockдЄ≠пЉМйїШиЃ§Blockе§Іе∞ПдЄЇ64MBгАВ

2. еНХдЄ™NamenodeзЪДHDFSжЮґжЮДзЪДе±АйЩРжАІ
2.1 NamespaceпЉИеСљеРНз©ЇйЧіпЉЙзЪДйЩРеИґ
зФ±дЇОNamenodeеЬ®еЖЕе≠ШдЄ≠е≠ШеВ®жЙАжЬЙзЪДеЕГжХ∞жНЃпЉИmetadataпЉЙпЉМеЫ†ж≠§еНХдЄ™NamenodeжЙАиГље≠ШеВ®зЪДеѓєи±°пЉИжЦЗдїґ+еЭЧпЉЙжХ∞зЫЃеПЧеИ∞NamenodeжЙАеЬ®JVMзЪДheap sizeзЪДйЩРеИґгАВ50GзЪДheapиГље§Яе≠ШеВ®20дЇњпЉИ200 millionпЉЙдЄ™еѓєи±°пЉМињЩ20дЇњдЄ™еѓєи±°жФѓжМБ4000дЄ™datanodeпЉМ12PBзЪДе≠ШеВ®пЉИеБЗиЃЊжЦЗдїґеє≥еЭЗе§Іе∞ПдЄЇ40MBпЉЙгАВ
йЪПзЭАжХ∞жНЃзЪДй£ЮйАЯеҐЮйХњпЉМе≠ШеВ®зЪДйЬАж±ВдєЯйЪПдєЛеҐЮйХњгАВеНХдЄ™datanodeдїО4TеҐЮйХњеИ∞36TпЉМйЫЖзЊ§зЪДе∞ЇеѓЄеҐЮйХњеИ∞8000дЄ™datanodeгАВе≠ШеВ®зЪДйЬАж±ВдїО12PBеҐЮйХњеИ∞е§ІдЇО100PBгАВ
2.2 жАІиГљзЪДзУґйҐИ
зФ±дЇОжШѓеНХдЄ™NamenodeзЪДHDFSжЮґжЮДпЉМеЫ†ж≠§жХідЄ™HDFSжЦЗдїґз≥їзїЯзЪДеРЮеРРйЗПеПЧйЩРдЇОеНХдЄ™NamenodeзЪДеРЮеРРйЗПгАВжѓЂжЧ†зЦСйЧЃпЉМињЩе∞ЖжИРдЄЇдЄЛдЄАдї£MapReduceзЪДзУґйҐИгАВ
2.3 йЪФз¶їйЧЃйҐШ
зФ±дЇОHDFSдїЕжЬЙдЄАдЄ™NamenodeпЉМжЧ†ж≥ХйЪФз¶їеРДдЄ™з®ЛеЇПпЉМеЫ†ж≠§HDFSдЄКзЪДдЄАдЄ™еЃЮй™Мз®ЛеЇПе∞±еЊИжЬЙеПѓиГљељ±еУНжХідЄ™HDFSдЄКињРи°МзЪДз®ЛеЇПгАВйВ£дєИеЬ®HDFS FederationдЄ≠пЉМеПѓдї•зФ®дЄНеРМзЪДNamespaceжЭ•йЪФз¶їдЄНеРМзЪДзФ®жИЈеЇФзФ®з®ЛеЇПпЉМдљњеЊЧдЄНеРМNamespace VolumeдЄ≠зЪДз®ЛеЇПзЫЄдЇТдЄНељ±еУНгАВ
2.4 йЫЖзЊ§зЪДеПѓзФ®жАІ
еЬ®еП™жЬЙдЄАдЄ™NamenodeзЪДHDFSдЄ≠пЉМж≠§NamenodeзЪДеЃХжЬЇжЧ†зЦСдЉЪеѓЉиЗіжХідЄ™йЫЖзЊ§дЄНеПѓзФ®гАВ
2.5 NamespaceеТМBlock ManagementзЪДзіІеѓЖиА¶еРИ
ељУеЙНеЬ®NamenodeдЄ≠зЪДNamespaceеТМBlock ManagementзїДеРИзЪДзіІеѓЖиА¶еРИеЕ≥з≥їдЉЪеѓЉиЗіе¶ВжЮЬжГ≥и¶БеЃЮзО∞еП¶е§ЦдЄАе•ЧNamenodeжЦєж°ИжѓФиЊГеЫ∞йЪЊпЉМиАМдЄФдєЯйЩРеИґдЇЖеЕґдїЦжГ≥и¶БзЫіжО•дљњзФ®еЭЧе≠ШеВ®зЪДеЇФзФ®гАВ
2.6 дЄЇдїАдєИзЇµеРСжЙ©е±ХзЫЃеЙНзЪДNamenodeдЄНеПѓи°МпЉЯжѓФе¶Ве∞ЖNamenodeзЪДHeapз©ЇйЧіжЙ©е§ІеИ∞512GBгАВ
ињЩж†ЈзЇµеРСжЙ©е±ХеЄ¶жЭ•зЪДзђђдЄАдЄ™йЧЃйҐШе∞±жШѓеРѓеК®йЧЃйҐШпЉМеРѓеК®иК±иієзЪДжЧґй׳姙йХњгАВељУеЙНеЕЈжЬЙ50GB Heap NamenodeзЪДHDFSеРѓеК®дЄАжђ°е§Іж¶ВйЬАи¶Б30еИЖйТЯеИ∞2е∞ПжЧґпЉМйВ£512GBзЪДйЬАи¶Бе§ЪдєЕпЉЯ
зђђдЇМдЄ™жљЬеЬ®зЪДйЧЃйҐШе∞±жШѓNamenodeеЬ®Full GCжЧґпЉМе¶ВжЮЬеПСзФЯйФЩиѓѓе∞ЖдЉЪеѓЉиЗіжХідЄ™йЫЖзЊ§еЃХжЬЇгАВ
зђђдЄЙдЄ™йЧЃйҐШжШѓеѓєе§ІJVM HeapињЫи°Ми∞ГиѓХжѓФиЊГеЫ∞йЪЊгАВдЉШеМЦNamenodeзЪДеЖЕе≠ШдљњзФ®жАІдїЈжѓФжѓФиЊГдљОгАВ
3. дЄЇдїАдєИи¶БеЉХеЕ•Federation
еЉХеЕ•FederationзЪДжЬАдЄїи¶БеОЯеЫ†жШѓзЃАеНХпЉМеЕґзЃАеНХжАІжШѓдЄОзЬЯж≠£зЪДеИЖеЄГеЉПNamenodeзЫЄжѓФиАМи®АзЪДгАВFederationиГље§ЯењЂйАЯзЪДиІ£еЖ≥дЇЖе§ІйГ®еИЖеНХNamenode HDFSзЪДйЧЃйҐШгАВ
FederationжШѓзЃАеНХй≤Бж£ТзЪДиЃЊиЃ°пЉМзФ±дЇОиБФзЫЯдЄ≠еРДдЄ™NamenodeдєЛйЧіжШѓзЫЄдЇТзЛђзЂЛзЪДгАВFederationжХідЄ™ж†ЄењГиЃЊиЃ°еЃЮзО∞е§Іж¶ВзФ®дЇЖ3.5дЄ™жЬИгАВе§ІйГ®еИЖжФєеПШжШѓеЬ®DatanodeгАБConfigеТМToolsпЉМиАМNamenodeжЬђиЇЂзЪДжФєеК®йЭЮеЄЄе∞СпЉМињЩж†ЈNamenodeеОЯеЕИзЪДй≤Бж£ТжАІдЄНдЉЪеПЧеИ∞ељ±еУНгАВжѓФеИЖеЄГеЉПзЪДNamenodeзЃАеНХпЉМиЩљзДґињЩзІНеЃЮзО∞зЪДжЙ©е±ХжАІжѓФиµЈзЬЯж≠£зЪДеИЖеЄГеЉПзЪДNamenodeи¶Бе∞ПдЇЫпЉМдљЖжШѓеПѓдї•ињЕйАЯжї°иґ≥йЬАж±ВгАВеП¶е§ЦдЄАдЄ™еОЯеЫ†жШѓFederationиЙѓе•љзЪДеРСеРОеЕЉеЃєжАІпЉМеЈ≤жЬЙзЪДеНХNamenodeзЪДйГ®зљ≤йЕНзљЃдЄНйЬАи¶БдїїдљХжФєеПШе∞±еПѓдї•зїІзї≠еЈ•дљЬгАВ
еЫ†ж≠§FederationпЉИиБФзЫЯпЉЙжШѓжЬ™жЭ•еПѓйАЙзЪДжЦєж°ИдєЛдЄАгАВеЬ®FederationжЮґжЮДдЄ≠еПѓдї•жЧ†зЉЭзЪДжФѓжМБзЫЃеЙНеНХNamenodeжЮґжЮДдЄ≠зЪДйЕНзљЃгАВ
4. HDFS Federation
HDFS FederationдљњзФ®дЇЖе§ЪдЄ™зЛђзЂЛзЪДNamenode/namespaceжЭ•дљњеЊЧHDFSзЪДеСљеРНжЬНеК°иГље§Яж∞іеє≥жЙ©е±ХгАВеЬ®HDFS FederationдЄ≠зЪДNamenodeдєЛйЧіжШѓиБФзЫЯеЕ≥з≥їпЉМдїЦдїђдєЛйЧізЫЄдЇТзЛђзЂЛдЄФдЄНйЬАи¶БзЫЄдЇТеНПи∞ГгАВHDFS FederationдЄ≠зЪДNamenodeжПРдЊЫдЇЖжПРдЊЫдЇЖеСљеРНз©ЇйЧіеТМеЭЧзЃ°зРЖеКЯиГљгАВHDFS FederationдЄ≠зЪДdatanode襀жЙАжЬЙзЪДNamenodeзФ®дљЬеЕђеЕ±е≠ШеВ®еЭЧзЪДеЬ∞жЦєгАВжѓПдЄАдЄ™datanodeйГљдЉЪеРСжЙАеЬ®йЫЖзЊ§дЄ≠жЙАжЬЙзЪДNamenodeж≥®еЖМпЉМеєґдЄФдЉЪеС®жЬЯжАІзЪДеПСйАБењГиЈ≥еТМеЭЧдњ°жБѓжК•еСКпЉМеРМжЧґе§ДзРЖжЭ•иЗ™NamenodeзЪДжМЗдї§гАВ
4.1 Federation HDFSдЄОељУеЙНHDFSзЪДжѓФиЊГ
- ељУеЙНHDFSеП™жЬЙдЄАдЄ™еСљеРНз©ЇйЧіпЉИNamespaceпЉЙпЉМеЃГдљњзФ®еЕ®йГ®зЪДеЭЧгАВиАМFederation HDFSдЄ≠жЬЙе§ЪдЄ™зЛђзЂЛзЪДеСљеРНз©ЇйЧіпЉИNamespaceпЉЙпЉМеєґдЄФжѓПдЄАдЄ™еСљеРНз©ЇйЧідљњзФ®дЄАдЄ™еЭЧ汆пЉИblock poolпЉЙгАВ
- ељУеЙНHDFSдЄ≠еП™жЬЙдЄАзїДеЭЧгАВиАМFederation HDFSдЄ≠жЬЙе§ЪзїДзЛђзЂЛзЪДеЭЧгАВеЭЧ汆пЉИblock poolпЉЙе∞±жШѓе±ЮдЇОеРМдЄАдЄ™еСљеРНз©ЇйЧізЪДдЄАзїДеЭЧгАВ
- ељУеЙНHDFSзФ±дЄАдЄ™NamenodeеТМдЄАзїДdatanodeзїДжИРгАВиАМFederation HDFSзФ±е§ЪдЄ™NamenodeеТМдЄАзїДdatanodeпЉМжѓПдЄАдЄ™datanodeдЉЪдЄЇе§ЪдЄ™еЭЧ汆пЉИblock poolпЉЙе≠ШеВ®еЭЧгАВ
4.2 Block Pool(еЭЧ汆)
жЙАи∞УBlock pool(еЭЧ汆)е∞±жШѓе±ЮдЇОеНХдЄ™еСљеРНз©ЇйЧізЪДдЄАзїДblock(еЭЧ)гАВжѓПдЄАдЄ™datanodeдЄЇжЙАжЬЙзЪДblock poolе≠ШеВ®еЭЧгАВDatanodeжШѓдЄАдЄ™зЙ©зРЖж¶ВењµпЉМиАМblock poolжШѓдЄАдЄ™йЗНжЦ∞е∞ЖblockеИТеИЖзЪДйАїиЊСж¶ВењµгАВеРМдЄАдЄ™datanodeдЄ≠еПѓдї•е≠ШзЭАе±ЮдЇОе§ЪдЄ™block poolзЪДе§ЪдЄ™еЭЧгАВBlock poolеЕБиЃЄдЄАдЄ™еСљеРНз©ЇйЧіеЬ®дЄНйАЪзЯ•еЕґдїЦеСљеРНз©ЇйЧізЪДжГЕеЖµдЄЛдЄЇдЄАдЄ™жЦ∞зЪДblockеИЫеїЇBlock IDгАВеРМжЧґпЉМдЄАдЄ™Namenode姱жХИдЄНдЉЪељ±еУНеЕґдЄЛзЪДdatanodeдЄЇеЕґдїЦNamenodeзЪДжЬНеК°гАВ
ељУdatanodeдЄОNamenodeеїЇзЂЛиБФз≥їеєґеЉАеІЛдЉЪиѓЭеРОиЗ™еК®еїЇзЂЛBlock poolгАВжѓПдЄ™blockйГљжЬЙдЄАдЄ™еФѓдЄАзЪДж†ЗиѓЖпЉМињЩдЄ™ж†ЗиѓЖжИСдїђзІ∞дєЛдЄЇжЙ©е±ХзЪДеЭЧIDпЉИExtended Block IDпЉЙ= BlockID+BlockIDгАВињЩдЄ™жЙ©е±ХзЪДеЭЧIDеЬ®HDFSйЫЖзЊ§дєЛйЧійГљжШѓеФѓдЄАзЪДпЉМињЩдЄЇдї•еРОйЫЖзЊ§ељТеєґеИЫйА†дЇЖжЭ°дїґгАВ
DatanodeдЄ≠зЪДжХ∞жНЃзїУжЮДйГљйАЪињЗеЭЧ汆IDпЉИBlockPoolIDпЉЙ糥еЉХпЉМеН≥datanodeдЄ≠зЪДBlockMapпЉМstorageз≠ЙйГљйАЪињЗBPID糥еЉХгАВ
еЬ®HDFSдЄ≠пЉМжЙАжЬЙзЪДжЫіжЦ∞гАБеЫЮжїЪйГљжШѓдї•NamenodeеТМBlockPoolдЄЇеНХеЕГеПСзФЯзЪДгАВеН≥еРМдЄАHDFS FederationдЄ≠дЄНеРМзЪДNamenode/BlockPoolдєЛйЧіж≤°жЬЙдїАдєИеЕ≥з≥їгАВ
Hadoop V0.23зЙИжЬђдЄ≠Block PoolзЪДзЃ°зРЖеКЯиГљдЊЭзДґжФЊеЬ®дЇЖNamenodeдЄ≠пЉМе∞ЖжЭ•зЪДзЙИжЬђдЄ≠дЉЪе∞ЖBlock PoolзЪДзЃ°зРЖеКЯиГљзІїеК®зЪДжЦ∞зЪДеКЯиГљиКВзВєдЄ≠гАВ
4.3 DatanodeзЪДжФєињЫ
еЬ®datanodeдЄ≠пЉМеѓєеЇФдЇОжѓПдЄ™NamnodeйГљжЬЙдЄАжЭ°зЫЄеЇФзЪДзЇњз®ЛгАВжѓПдЄ™datanodeдЉЪеОїжѓПдЄАдЄ™Namenodeж≥®еЖМпЉМеєґдЄФеС®жЬЯжАІзЪДзїЩжЙАжЬЙзЪДNamenodeеПСйАБењГиЈ≥еПКdatanodeзЪДдљњзФ®жК•еСКгАВDatanodeињШдЉЪзїЩNamenodeеПСйАБеЕґжЙАеЬ®зЪДblock poolзЪДblock reportпЉИеЭЧжК•еСКпЉЙгАВзФ±дЇОжЬЙе§ЪдЄ™NamenodeеРМжЧґе≠ШеЬ®пЉМеЫ†ж≠§дїїдљХдЄАдЄ™NamenodeйГљеПѓдї•йЪПжЧґеК®жАБеК†еЕ•гАБеИ†йЩ§еТМжЫіжЦ∞гАВ
4.4 FederationдЄ≠зЪДеЕґдїЦжЦєйЭҐзЪДжФєињЫ
- жПРдЊЫдЇЖеЈ•еЕЈпЉМеѓєдЇОNamenodeзЪДеИЭеІЛеМЦеТМйААељєзЪДзЫСжОІеТМзЃ°зРЖгАВ
- еЕБиЃЄеЬ®datanodeзЇІеИЂжИЦиАЕblock poolзЇІеИЂзЪДиіЯиљљеЭЗи°°гАВ
- DatanodeзЪДеРОеП∞еЃИжК§ињЫз®ЛпЉМдЄЇFederationжЙАеБЪзЪДз£БзЫШеТМзЫЃељХжЙЂжППгАВ
- жПРдЊЫдЇЖжШЊз§ЇNamenodeзЪДBlock poolзЪДдљњзФ®зКґжАБзЪДWeb UIгАВ
- ињШжПРдЊЫдЇЖеѓєеЕ®йГ®йЫЖзЊ§е≠ШеВ®дљњзФ®зКґжАБзЪДUIе±Хз§ЇгАВ
- еЬ®Web UIдЄ≠еИЧеЗЇдЇЖжЙАжЬЙзЪДNamenodeеПКеЕґзїЖиКВпЉМе¶ВNamenode-BlockPoolIDеТМе≠ШеВ®зЪДдљњзФ®зКґжАБпЉМ姱еОїиБФз≥їзЪДгАБжіїзЪДеТМж≠їзЪДеЭЧдњ°жБѓгАВињШжЬЙеЙНеЊАеРДдЄ™Namenode Web UIзЪДйУЊжО•гАВ
- DatanodeйААељєзКґжАБзЪДе±Хз§ЇгАВ
4.5 е§ЪеСљеРНз©ЇйЧізЪДзЃ°зРЖйЧЃйҐШ
еЬ®дЄАдЄ™йЫЖзЊ§дЄ≠йЬАи¶БеФѓдЄАзЪДеСљеРНз©ЇйЧіињШжШѓе§ЪдЄ™еСљеРНз©ЇйЧіпЉМж†ЄењГйЧЃйҐШеСљеРНз©ЇйЧідЄ≠жХ∞жНЃзЪДеЕ±дЇЂеТМиЃњйЧЃзЪДйЧЃйҐШгАВдљњзФ®еЕ®е±АеФѓдЄАзЪДеСљеРНз©ЇйЧіжШѓиІ£еЖ≥жХ∞жНЃеЕ±дЇЂеТМиЃњйЧЃзЪДдЄАзІНжЦєж≥ХгАВеЬ®е§ЪеСљеРНз©ЇйЧідЄЛпЉМжИСдїђињШеПѓдї•дљњзФ®Client Side Mount TableжЦєеЉПеБЪеИ∞жХ∞жНЃеЕ±дЇЂеТМиЃњйЧЃгАВ
е¶ВдЄКеЫЊжЙАз§ЇпЉМжѓПдЄ™жЈ±иЙ≤дЄЙиІТељҐдї£и°®дЄАдЄ™зЛђзЂЛзЪДеСљеРНз©ЇйЧіпЉМдЄКжЦєжµЕиЙ≤зЪДдЄЙиІТељҐдї£и°®дїОеЃҐжИЈиІТеЇ¶еОїиЃњйЧЃдЄЛжЦєзЪДе≠РеСљеРНз©ЇйЧігАВеРДдЄ™жЈ±иЙ≤зЪДеСљеРНз©ЇйЧіMountеИ∞жµЕиЙ≤зЪДи°®дЄ≠пЉМеЃҐжИЈеПѓдї•иЃњйЧЃдЄНеРМзЪДжМВиљљзВєжЭ•иЃњйЧЃдЄНеРМзЪДеСљеРНз©ЇйЧіпЉМињЩе∞±е¶ВеРМеЬ®Linuxз≥їзїЯдЄ≠иЃњйЧЃдЄНеРМжМВиљљзВєдЄАж†ЈгАВињЩе∞±жШѓHDFS FederationдЄ≠еСљеРНз©ЇйЧізЃ°зРЖзЪДеЯЇжЬђеОЯзРЖпЉЪе∞ЖеРДдЄ™еСљеРНз©ЇйЧіжМВиљљеИ∞еЕ®е±АmountпЉНtableдЄ≠пЉМе∞±еПѓдї•еБЪе∞ЖжХ∞жНЃеИ∞еЕ®е±АеЕ±дЇЂпЉЫеРМж†ЈзЪДеСљеРНз©ЇйЧіжМВиљљеИ∞дЄ™дЇЇзЪДmount-tableдЄ≠пЉМињЩе∞±жИРдЄЇеЇФзФ®з®ЛеЇПеПѓиІБзЪДеСљеРНз©ЇйЧіиІЖеЫЊгАВ
4.6 Namespace VolumeпЉИеСљеРНз©ЇйЧіеНЈпЉЙ
дЄАдЄ™NamespaceеТМеЃГзЪДBlock PoolеРИеЬ®дЄАиµЈзІ∞дљЬNamespace VolumeгАВNamespace VolumeжШѓдЄАдЄ™зЛђзЂЛеЃМжХізЪДзЃ°зРЖеНХеЕГгАВељУдЄАдЄ™Namenode/Namespace襀еИ†йЩ§пЉМдЄОдєЛзЫЄеѓєеЇФзЪДBlock PoolдєЯдєЯ襀еИ†йЩ§гАВеЬ®еНЗзЇІжЧґжѓПдЄАдЄ™Namespace VolumeдєЯдЉЪжХідљУдљЬдЄЇдЄАдЄ™еНХеЕГгАВ
4.7 ClusterID
еЬ®HDFS FederationдЄ≠жЈїеК†дЇЖCluster IDзФ®жЭ•еМЇеИЖйЫЖзЊ§дЄ≠зЪДжѓПдЄ™иКВзВєгАВељУж†ЉеЉПеМЦдЄАдЄ™NamenodeжЧґпЉМињЩдЄ™ClusterIDдЉЪиЗ™еК®зФЯжИРжИЦиАЕжЙЛеК®жПРдЊЫгАВеЬ®ж†ЉеЉПеМЦеРМдЄАйЫЖзЊ§дЄ≠еЕґдїЦNamenodeжЧґдЉЪзФ®еИ∞ињЩдЄ™ClusterIDгАВ
4.8 HDFS FederationеѓєиАБзЙИжЬђзЪДHDFSжШѓеЕЉеЃєзЪД
ињЩзІНеЕЉеЃєжАІеПѓдї•дљњеЊЧеЈ≤жЬЙзЪДNamenodeйЕНзљЃдЄНйЬАи¶БдїїдљХжФєеПШзїІзї≠еЈ•дљЬгАВ
еЕЈдљУзЪДе¶ВдљХйЕНзљЃеТМзЃ°зРЖFederation HDFSпЉМиѓЈеПВиАГhttp://hadoop.apache.org/common/docs/r0.23.0/hadoop-yarn/hadoop-yarn-site/Federation.html#Federation_ConfigurationгАВ
еПВиАГиµДжЦЩпЉЪ
Hadoop is here:http://hortonworks.com/apache-hadoop-is-here
HDFS Federation:http://www.slideshare.net/ydn/hug-march-hdfs-federation
HDFS Federation:http://hadoop.apache.org/common/docs/r0.23.0/hadoop-yarn/hadoop-yarn-site/Federation.html
HDFS Federation hadoop submit 2011:http://www.slideshare.net/huguk/hdfs-federation-hadoop-summit2011
An Introduction to HDFS Federation:http://hortonworks.com/an-introduction-to-hdfs-federation/
еИЖдЇЂеИ∞пЉЪ






зЫЄеЕ≥жО®иНР
HDFS HAеТМFederationеЃЙи£ЕйГ®зљ≤жЦєж≥Х
еЬ®HDPзОѓеҐГзЪДеЯЇз°АдЄКпЉМеЕ≥дЇОHDFSиБФйВ¶+ViewFS+HAзЪДиѓ¶зїЖйЕНзљЃпЉМеѓєдЇОйЬАи¶БеЉХеЕ•HDFSиБФйВ¶зЙєжАІзЪДеЈ•дљЬжЬЙеЄЃеК©
hdfsзЪДжЇРз†БжЈ±еЕ•е≠¶дє†пЉМжПРеНЗhdfsзЪДдљњзФ®ж∞іеє≥
1. NameNodeжЮґжЮДзЪДе±АйЩРжАІ 2.HDFS FederationжЮґжЮДиЃЊиЃ° 3.HDFS FederationеЇФзФ®жАЭиАГ
4пЉО1пЉО2 HDFS Federation 308 4пЉО1пЉО3 DatanodeйАїиЊСзїУжЮД 310 4пЉО2 Datanodeе≠ШеВ® 312 4пЉО2пЉО1 DatanodeеНЗзЇІжЬЇеИґ 312 4пЉО2пЉО2 Datanodeз£БзЫШе≠ШеВ®зїУжЮД 315 4пЉО2пЉО3 DataStorageеЃЮзО∞ 317 4пЉО3 жЦЗдїґз≥їзїЯжХ∞жНЃйЫЖ 334 4пЉО3пЉО1...
зђђ3~5зЂ†еИЖеИЂдїЛзїНдЇЖNamenodeгАБDatanodeдї•еПКHDFSеЃҐжИЈзЂѓињЩдЄЙдЄ™зїДдїґзЪДеЃЮзО∞зїЖиКВпЉМеРМжЧґз©њжПТдїЛзїНдЇЖHDFS 2.XзЪДжЦ∞зЙєжАІпЉМдЊЛе¶ВNamenode HAгАБFederation Namenodeз≠ЙгАВ йШЕиѓїгАКHadoop 2.X HDFSжЇРз†БеЙЦжЮРгАЛеПѓдї•еЄЃеК©иѓїиАЕдїОжЮґжЮДиЃЊиЃ°дЄО...
зђђ3~5зЂ†еИЖеИЂдїЛзїНдЇЖNamenodeгАБDatanodeдї•еПКHDFSеЃҐжИЈзЂѓињЩдЄЙдЄ™зїДдїґзЪДеЃЮзО∞зїЖиКВпЉМеРМжЧґз©њжПТдїЛзїНдЇЖHDFS 2.XзЪДжЦ∞зЙєжАІпЉМдЊЛе¶ВNamenode HAгАБFederation Namenodeз≠ЙгАВ йШЕиѓїгАКHadoop 2.X HDFSжЇРз†БеЙЦжЮРгАЛеПѓдї•еЄЃеК©иѓїиАЕдїОжЮґжЮДиЃЊиЃ°дЄО...
1. жАІиГљжМСжИШ 2. жАІиГљдЉШеМЦ 2. дЉШеМЦжЦєж°И 4. еИ†йЩ§еЭЧдЄ™жХ∞еПѓйЕНзљЃ 5. HDFS Federation 1. зЛђзЂЛйЫЖзЊ§ж®°еЉПеЉКзЂѓ 2.Federation
HDFS Federation HDFS Snapshots NFSv3 access to data in HDFS Support for running Hadoop on Microsoft Windows Binary Compatibility for MapReduce applications built on hadoop-1.x Substantial amount of ...
Cloudera Hadoop 5&HadoopйЂШйШґзЃ°зРЖеПКи∞ГдЉШ...HDFS FederationеЃЮзО∞з≠Й 2гАБжР≠еїЇжЬђеЬ∞YumйГ®зљ≤CDH5зЪДйЗНи¶БзїДдїґеТМдЉШеМЦйЕНзљЃ 3гАБImpalaгАБOozieеТМHueзЪДйГ®зљ≤гАБдљњзФ®жУНдљЬеПКи∞ГдЉШ 4гАБHadoopеЃЙеЕ®иЃ§иѓБеПКжОИжЭГзЃ°зРЖ 5гАБHadoopеРДзїДдїґжАІиГљи∞ГдЉШ
2.1. 2.2. 2.3. 2.4. 2.5. 2.6. 2.1. дњЃжФєйЕНзљЃжЦЗдїґ 2.2. еРѓеК® JournalNode
YarnйЕНзљЃзЫЄеЕ≥зЪДжЦЗж°£пЉМеМЕжЛђHDFS FederationеТМжЮґжЮДзЪДйЕНзљЃ
Then, it dives deep into Hadoop 2.0 specific features such as YARN and HDFS Federation. This book is a step-by-step guide that focuses on advanced Hadoop concepts and aims to take your Hadoop ...
Federation ViewFs Guide HDFS Snapshots HDFS Architecture Edits Viewer Image Viewer Permissions and HDFS Quotas and HDFS HFTP C API libhdfs WebHDFS REST API HttpFS Gateway Short Circuit ...
еЕґдЄ≠MRv2ињШеЊИдЄНжИРзЖЯпЉМеПѓHDFSзЪДжЦ∞еКЯиГљеЈ≤зїПеЯЇжЬђеПѓзФ®пЉМе∞§еЕґжШѓеЕґдЄ≠зЪДзЪДHighAvailability(дї•дЄЛзЃАзІ∞HA)еТМFederationгАВClouderaдєЯдЇО7жЬИеИґдљЬдЇЖCDH4.0.1пЉМеМЕеРЂдЇЖHadoop2.0зЪДиѓЄе§ЪжЦ∞еКЯиГљеТМзїДдїґпЉМдЇОжШѓжИСдїђе∞±еЯЇдЇОCDH4.0.1ињЫи°МдЇЖHA...
вЉ§жХ∞жНЃињРзїівЊѓиѓХйҐШжХізРЖ HDFSжАїзїУпЉЪ 1гАБHDFSжШѓе¶ВдљХиІ£еЖ≥вЉ§иІДж®°жХ∞жНЃзЪДе≠ШеВ®еТМзЃ°зРЖзЪД 2гАБHDFSзЪДжЮґжЮДеОЯзРЖеТМеРДж†ЄвЉЉзїДдїґзЪДдљЬвљ§еПКеЕ≥з≥ї 3гАБHDFSвљВдїґз≥їзїЯжХ∞жНЃзЪДиѓїеЖЩжµБз®Л 4гАБHDFSзЪДHAзЪДжЮґжЮДеОЯзРЖеПКж†ЄвЉЉ 5гАБHDFSзЪДFederationжЬЇеИґ 6...
пЉИ2пЉЙNameNode Federation пЉИ3пЉЙHDFS ењЂзЕІпЉИsnapshotпЉЙ пЉИ4пЉЙHDFS зЉУе≠ШпЉИin-memory cacheпЉЙ пЉИ5пЉЙHDFS ACL пЉИ6пЉЙеЉВжЮДе±ВзЇІе≠ШеВ®зїУжЮДпЉИHeterogeneous Storage hierarchyпЉЙ 2. YARNжЦ∞зЙєжАІеЙЦжЮРеПКеЇФзФ® пЉИ1пЉЙ...
е§ІжХ∞жНЃжКАжЬѓеОЯзРЖдЄОеЇФзФ® 1. жХ∞жНЃдЇІзФЯжЦєеЉПзЪДеПШйЭ©дЄїи¶БзїПеОЖдЇЖдЄЙдЄ™йШґжЃµпЉМдї•дЄЛ... 14еНХйАЙ(2еИЖ)дЄЛеИЧиѓіж≥ХйФЩиѓѓзЪДжШѓпЉИпЉЙ [еНХйАЙйҐШ] * A.HDFS HAеПѓдї•иІ£еЖ≥еНХзВєжХЕйЪЬйЧЃйҐШ B.HDFS FederationдљњеЊЧHDFSзЪДеСљеРНжЬНеК°иГље§Яж∞іеє≥жЙ©е±Х C.зђђдЇМеРНзІ∞иКВ
federation)вА©andвА©henceвА©multipleвА©namespaces.вА©ViewfsвА©isвА©analogousвА©toвА©theвА©clientвА©sideвА©mountвА©tablesвА© inвА©someвА©Unix/LinuxвА©systems.вА©ViewfsвА©canвА©beвА©usedвА©toвА©createвА©personalizedвА©namespace...